前端监控
什么是前端监控?
它指的是通过一定的手段来获取用户行为以及跟踪产品在用户端的使用情况,并以监控数据为基础,为产品优化指明方向,为用户提供更加精确、完善的服务。
前端监控
一般来讲一个成熟的产品,运营与产品团队需要关注用户在产品内的行为记录,通过用户的行为记录来优化产品,研发与测试团队则需要关注产品的性能以及异常,确保产品的性能体验以及安全迭代。
「所以前端监控一般也分为三大类:」
数据监控(监控用户行为)
- PV/UV: PV(page view):即页面浏览量或点击量;UV(unique visitor):指访问某个站点或点击某条新闻的不同 IP 地址的人数
- 用户在每一个页面的停留时间
- 用户通过什么入口来访问该网页
- 用户在相应的页面中触发的行为,等…
统计这些数据是有意义的,比如我们知道了用户来源的渠道,可以促进产品的推广,知道用户在每一个页面停留的时间,可以针对停留较长的页面,增加广告推送等等。
性能监控(监控页面性能)
- 不同用户,不同机型和不同系统下的首屏加载时间
- 白屏时间
- http 等请求的响应时间
- 静态资源整体下载时间
- 页面渲染时间
- 页面交互动画完成时间,等…
这些性能监控的结果,可以展示前端性能的好坏,根据性能监测的结果可以进一步的去优化前端性能,尽可能的提高用户体验。
异常监控(监控产品、系统异常)
及时的上报异常情况,可以避免线上故障的发上。虽然大部分异常可以通过 try catch 的方式捕获,但是比如内存泄漏以及其他偶现的异常难以捕获。常见的需要监控的异常包括:
- Javascript 的异常监控
- 样式丢失的异常监控
数据采集
Performance — 前端性能监控
一、什么是performance
performance可以获取到当前页面中与性能相关的信息,可以检测到白屏时间、首屏时间、用户可操作的时间节点、页面总下载的时间、DNS查询的时间、TCP链接的时间等。
二、前端性能主要测试点
白屏时间:从打开网站到有内容渲染出来的时间点
首屏时间:首屏内容渲染完毕的时间节点
用户可操作时间节点:domready触发节点
总下载时间:window.onload的触发节点
新建个demo.html
其中 memory 是和内存相关的,navigation 是指来源相关的,timing是关键点时间。
performance.memory 含义是显示此刻内存占用的情况
jsHeapSizeLimit 表示内存大小的限制
totalJSHeapSize 表示总内存的大小
usedJSHeapSize 表示可使用的内存大小
如果 usedJSHeadSize 大于 totalJSHeadSize 的话,那么会出现内存泄露的问题,因此不允许出现这种情况
performance.navigation 含义是页面的来源信息
redirectCount 如果有重定向,页面通过几次重定向跳转而来,默认为0
type 表示页面打开方式,默认为0,可取值为0、1、2、255
0 (TYPE_NAVIGATE) 表示正常进入该页面(非刷新、非重定向)
1 (TYPE_RELOAD) 表示通过window.location.reload刷新的页面
2 (TYPE_BACK_FORWARD) 表示通过浏览器的前进、后退按钮进入的页面
255 (TYPE_RESERVED) 表示非以上方式进入页面
performance.onresourcetimingbufferfull 一个回调函数,会在浏览器的资源时间性能缓冲区满了的时候执行
performance.timeOrigin 是一系列时间点的基准点,精确到万分之一毫秒,动态的,刷新页面会改变
performance.timing 是一系列关键时间点,包含网络、解析等一系列时间数据
navigationStart 同一个浏览器上一个页面卸载结束时的时间戳。如果没有上一个页面,那么该值会和fetchStart的值相同
redirectStart 第一个http重定向开始的时间戳,如果没有重定向,或重定向到同一个不同的源,那么返回0
redirectEnd 最后一个http重定向完成时的时间戳。如果没有重定向,或重定向到一个不同的源,那么返回为0
fetchStart 浏览器准备好使用http请求抓取文档的时间(发生在检查本地缓存之前)
domainLookupStart DNS域名查询开始时间,如果使用了本地缓存或持久链接,该值则与fetchStart相同
domainLookupEnd DNS域名查询结束时间,如果使用了本地缓存或持久链接,该值则与fetchStart相同
connectStart http开始建立连接的时间,如果是持久链接的话,该值和fetchStart值相同,如果再在传输层发生了错误且需要重新建立链接的话,那么在这里显示的是新建立的链接开始时间
secureConnectionStart https链接开始的时间,如果不是安全链接,则值为0
connectEnd http完成建立链接的时间(完成握手),如果是持久链接的话,该值和fetchStart值相同,如果再在传输层发生了错误且需要重新建立链接的话,那么在这里显示的是新建立的链接开始时间
requestStart http请求读取真实文档开始的时间,包括从本地读取缓存,链接错误重连时
responseStart 开始接收到响应的时间(获取到第一个字节的时候),包括从本地读取缓存
responseEnd http响应全部接收完成时的时间(获取到最后一个字节)包括从本地读取缓存
unloadEventStart 前一个网页(和当前页面同域)unload的时间戳,如果没有前一个网页或前一个网页是不同的域的话,那么该值为0
unloadEventEnd 与unloadEventStart对应,返回是前一个网页unload事件绑定的回调函数执行完毕时间戳
domLoading 开始解析渲染DOM树的时间
domInteractive 完成解析DOM树的时间(只是DOM树解析完成,但是并没有开始加载网页的资源)
domContentLoadedEventStart DOM解析完成后,网页内资源加载开始的时间
domContentLoadedEventEnd DOM解析完成后,网页内资源加载完成的时间
domComplete DOM树解析完成,且资源也准备就绪的时间。Document.readyState变为complete,并将抛出readystatechange相关事件
loadEventStart load事件发送给文档。也即load回调函数开始执行的时间,如果没有绑定load事件,则该值为0
loadEventEnd load事件的回调函数执行完毕时间,如果没有绑定load事件,该值为0
测试点代码
重定向耗时 = redirectEnd - redirectStart
DNS查询耗时 = domainLookupEnd - domainLookupStart
TCP链接耗时 = connectEnd - connectStart
HTTP请求耗时 = responseEnd - responseStart
解析dom树耗时 = domComplete - domInteractive
白屏时间 = responseStart - navigationStart
DOMready时间 = domContentLoadedEventEnd - navigationStart
onload时间 = loadEventEnd - navigationStart
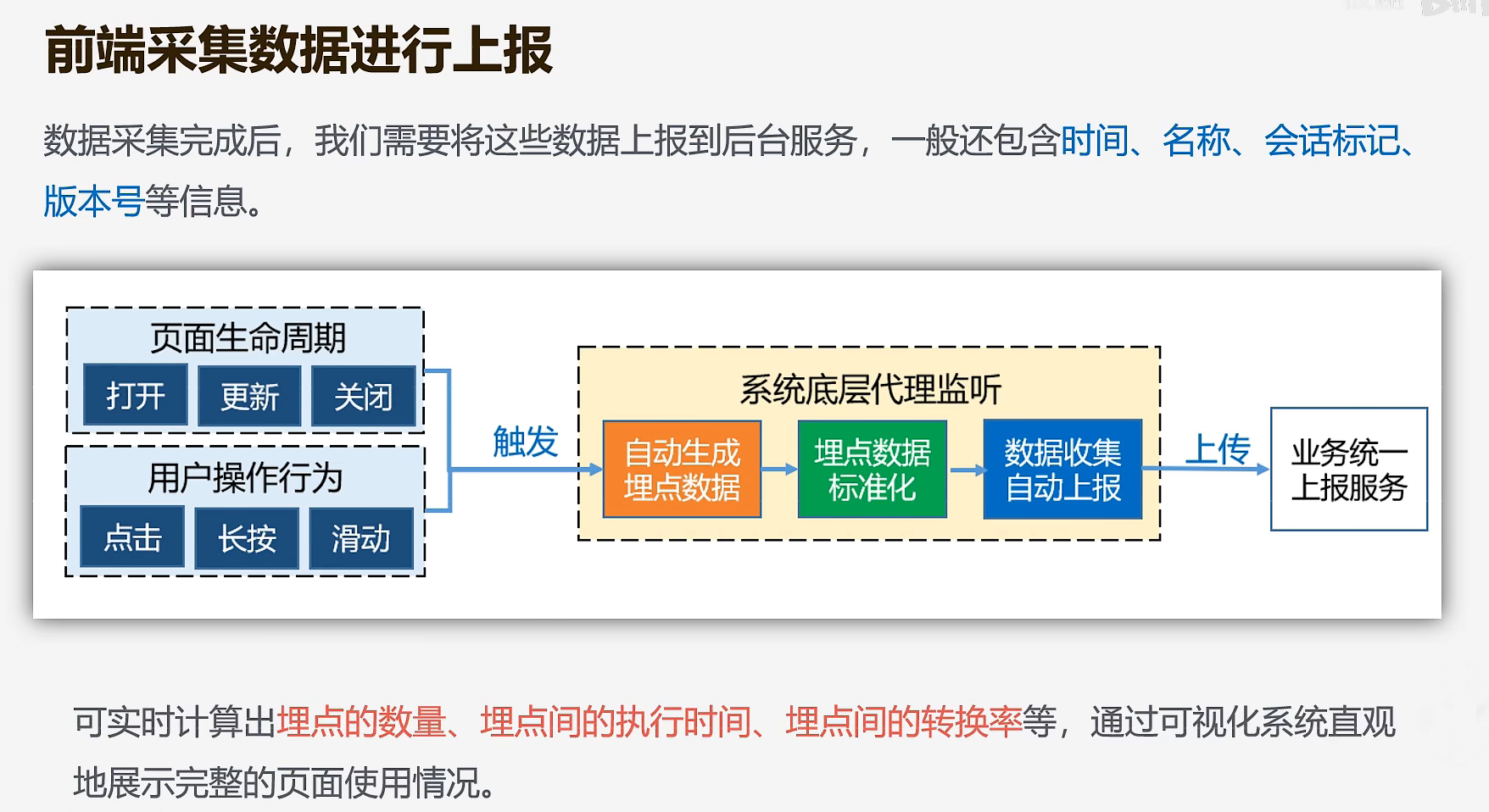
埋点上报
OK,上面我们说到了前端监控的三个分类,了解了一个产品需要监控哪些内容以及为什么需要监控这些内容,那么我们应该怎么实现前端监控呢?
实现前端监控,第一步肯定是将我们要监控的事项(数据)给收集起来,再提交给后台进行入库,最后再给数据分析组进行数据分析,最后处理好的数据再同步给运营或者是产品。数据收集的丰富性和准确性会直接影响到我们做前端监控的质量,因为我们会以此为基础,为产品的未来发展指引方向。
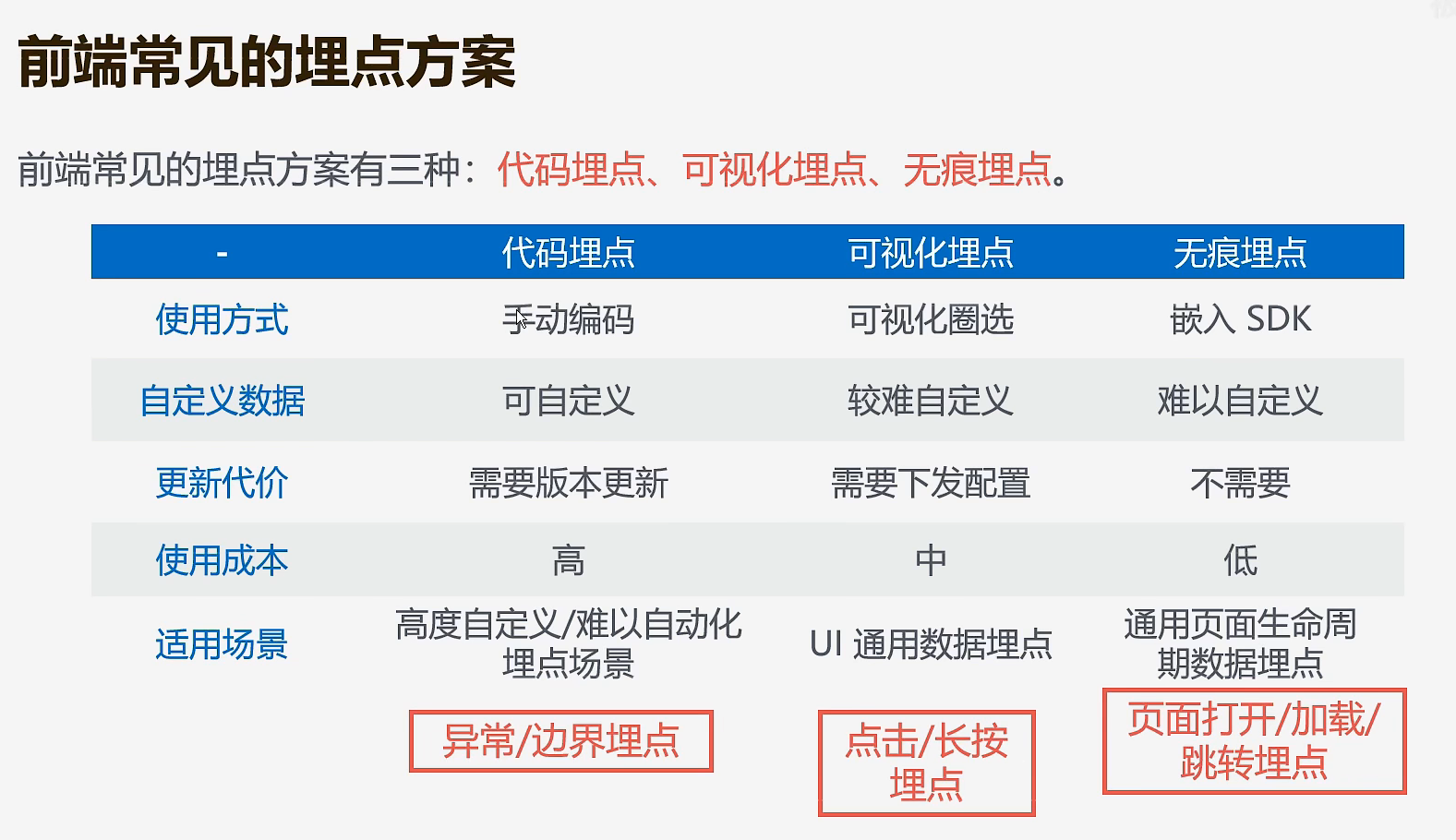
现在常见的埋点上报方法有三种:手动埋点、可视化埋点、无埋点
手动埋点
手动埋点,也叫代码埋点,即纯手动写代码,调用埋点 SDK 的函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据,像**[友盟]、[百度统计]**等第三方数据统计服务商大都采用这种方案。手动埋点让使用者可以方便地设置自定义属性、自定义事件;所以当你需要深入下钻,并精细化自定义分析时,比较适合使用手动埋点。
手动埋点的缺陷就是,项目工程量大,需要埋点的位置太多,而且需要产品开发运营之间相互反复沟通,容易出现手动差错,如果错误,重新埋点的成本也很高。
可视化埋点
通过可视化交互的手段,代替上述的代码埋点。将业务代码和埋点代码分离,提供一个可视化交互的页面,输入为业务代码,通过这个可视化系统,可以在业务代码中自定义的增加埋点事件等等,最后输出的代码耦合了业务代码和埋点代码。
可视化埋点的缺陷就是可以埋点的控件有限,不能手动定制。
无埋点
无埋点则是前端自动采集全部事件,上报埋点数据,由后端来过滤和计算出有用的数据。优点是前端只要一次加载埋点脚本,缺点是流量和采集的数据过于庞大,服务器性能压力山大。
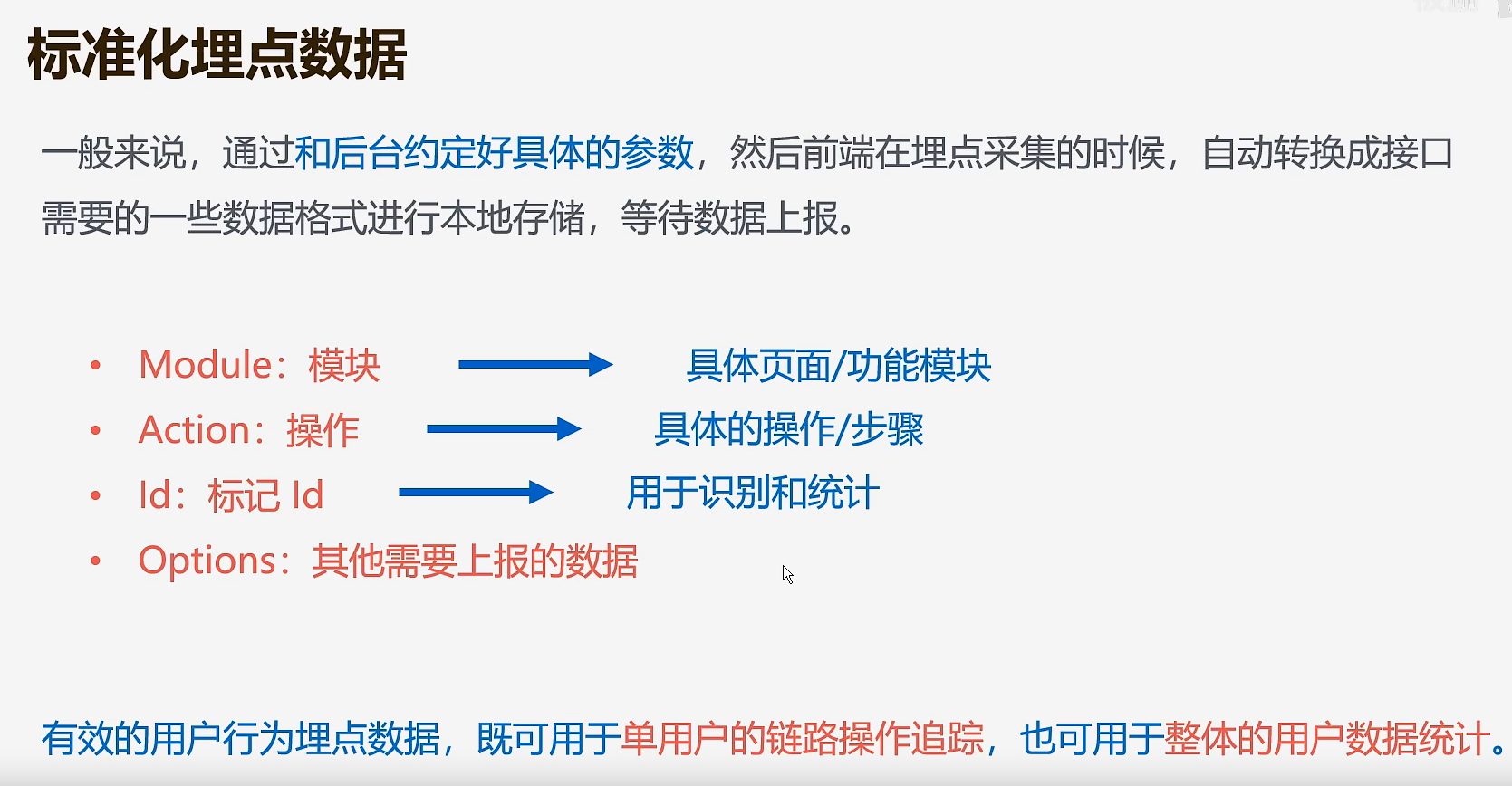
标准化埋点数据
日志存储
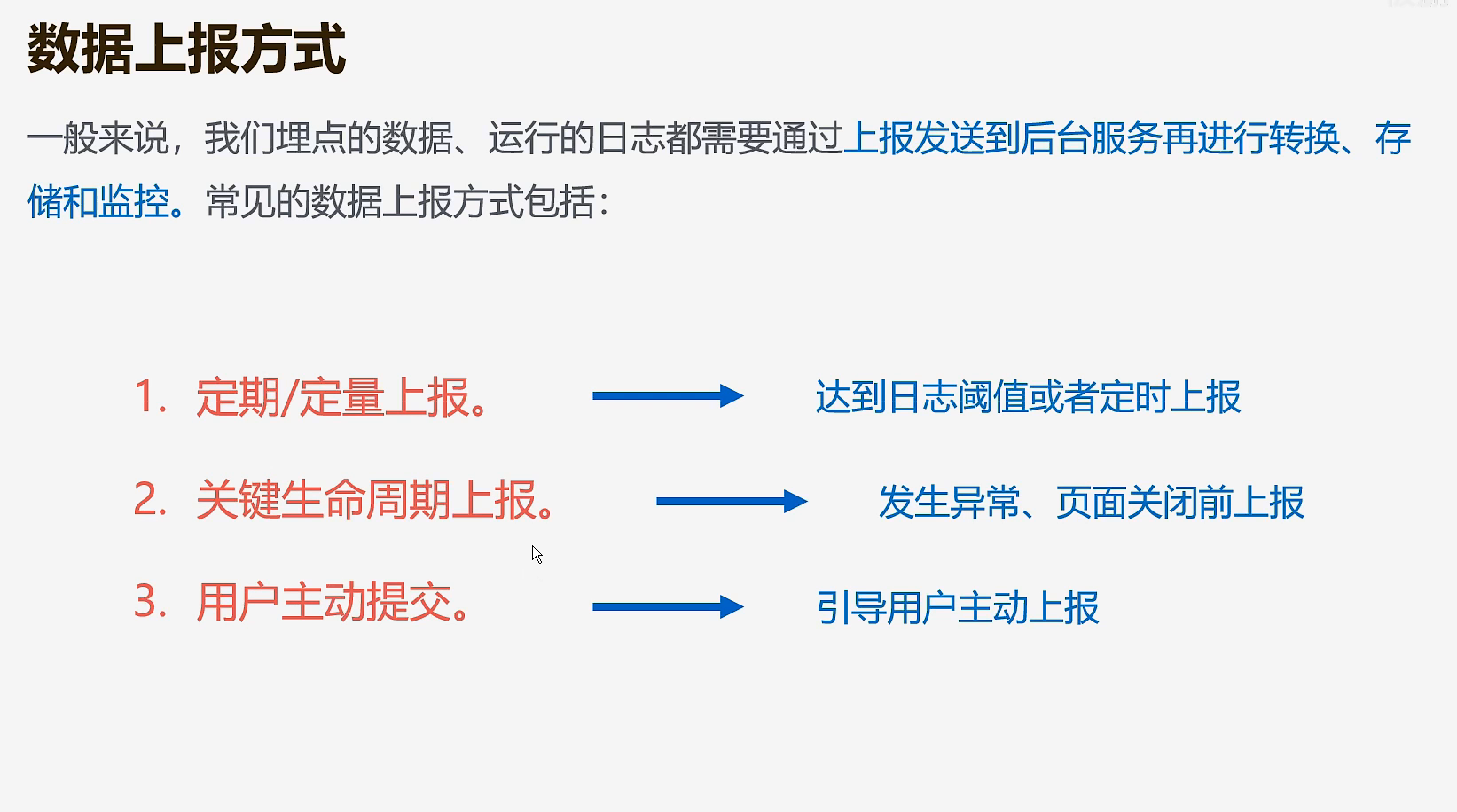
1.上传到服务器
- 日志量过大,可能导致传输、存储、查询速度等问题
- 过于频繁上报、会增加服务器压力
- 网络传输,容易导致日志丢失等问题
- 消耗前端资源,影响主业务
2.本地存储
- 需要引导用户手动提交日志
- 通过后台下发命令拉取日志
为什么都用GIF来做埋点?
发现过程
首先说一下我是怎么发现的,前一段时间,产品提了个需求,说我们现在的书籍曝光上报规范并不是他们想要的数据,并且以后所有页面的书籍上报都统一成最新规范。
曝光规范:
- 书籍出现在可视区并停留1秒,算作有效曝光
- 书籍不能重复曝光,假如它一直在可视区滚动时只能上报一次
- 当它移出可视区后再回到可视区,再按第一点进行曝光
OK,既然要所有页面统一,那就只能封装成通用库来使用了,这里实现逻辑就不贴了,想看的私聊我发你,主要的难点就是停留时长计算,以及曝光标记。
1 | |
具体业务逻辑之需要放在对应的callback里面,而上报逻辑开发者无需考虑,因为我底层已经统一处理好了。
然后我再测试的时候就发现,上报发的请求居然是通过图片发起的,并不是我们认为的接口上报。
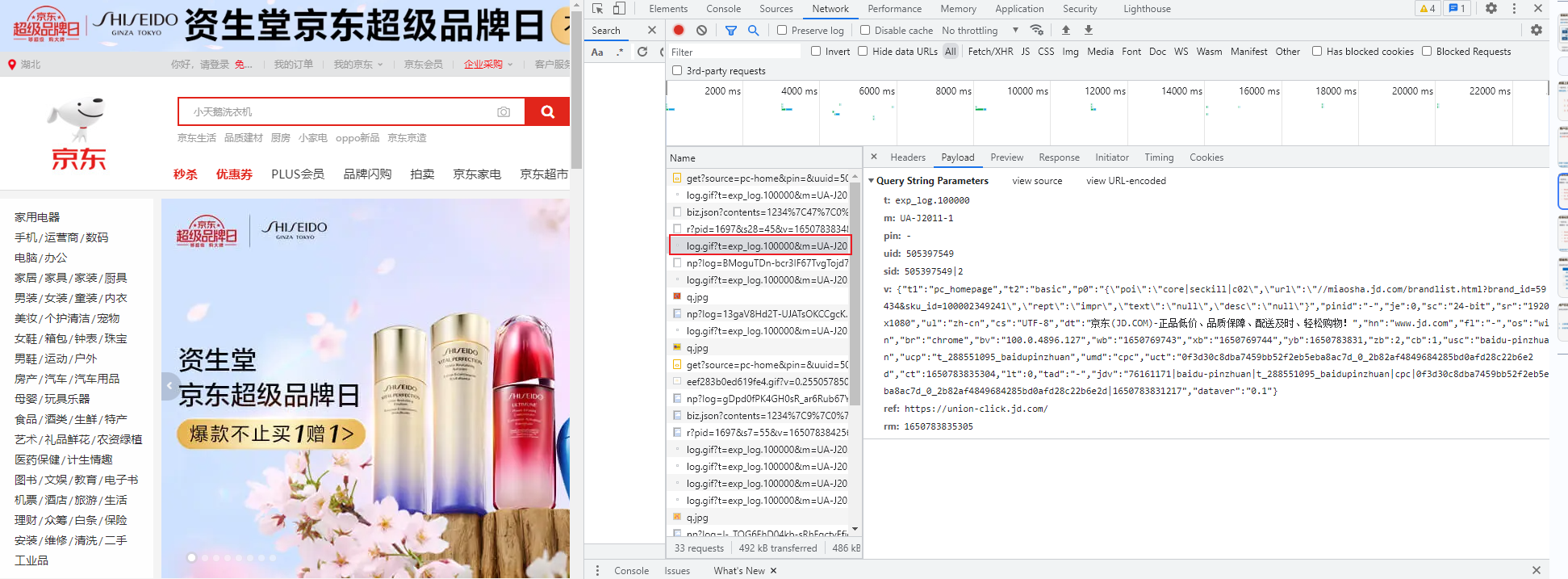
然后我去查了下资料,发现很多大厂的上报都是这么干的!
使用GIF上报的原因
向服务器端上报数据,可以通过请求接口,请求普通文件,或者请求图片资源的方式进行。只要能上报数据,无论是请求GIF文件还是请求其他普通文件(JS)或者是请求接口,服务器端其实并不关心具体的上报方式。那为什么所有系统都统一使用了请求GIF图片的方式上报数据呢?
「防止跨域」
一般而言,打点域名都不是当前域名,所以所有的接口请求都会构成跨域。而跨域请求很容易出现由于配置不当被浏览器拦截并报错,这是不能接受的。但图片的src属性并不会跨域,并且同样可以发起请求。(排除接口上报)
「防止阻塞页面加载,影响用户体验」
通常,创建资源节点后只有将对象注入到浏览器DOM树后,浏览器才会实际发送资源请求。反复操作DOM不仅会引发性能问题,而且载入js/css资源还会阻塞页面渲染,影响用户体验。
但是图片请求例外。构造图片打点不仅不用插入DOM,只要在js中new出Image对象就能发起请求,而且还没有阻塞问题,在没有js的浏览器环境中也能通过img标签正常打点,这是其他类型的资源请求所做不到的。(排除文件方式)
「相比PNG/JPG,GIF的体积最小」
最小的BMP文件需要74个字节,PNG需要67个字节,而合法的GIF,只需要43个字节。
同样的响应,GIF可以比BMP节约41%的流量,比PNG节约35%的流量。
1兆字节(mb)=1048576字节(b)
1048576/43 ≈ 24385
「并且大多采用的是1*1像素的透明GIF来上报」
1x1像素是最小的合法图片。而且,因为是通过图片打点,所以图片最好是透明的,这样一来不会影响页面本身展示效果,二者表示图片透明只要使用一个二进制位标记图片是透明色即可,不用存储色彩空间数据,可以节约体积。